Documentation
Introduction
Beyond Decentralized technology enables Fair Data Ownership and Independent Software Development.
- Version: 0.4.0
- Created: July 16th, 2022
- Updated: September 12th, 2022
Please feel free to email Artem if you need information beyond what is covered here.
At the core of Beyond Decentralized stack is relational database technology. It structures data in relational tables and exposes its structure as schemas. Developers are able to read these schemas and understand how data is structured. In turn, Applications are able to join data across multiple schemas and present it to the users.
Autonomous Interdependent Repositories enable use of relational databases in decentralized environments. Data is split into virtual Repositories. Repositories reside on user's devices in relational databases. Repository transaction logs are stored independently, on shared file systems like Filecoin.
AIR Whitepaper
Autonomous Interdependent Repositories (AIR) Whitepaper - Download
Technologies
Beyond Decentralized is focused on data decentralization while keeping data structured and understandable.
-
AIRport is
the founding and core project of Beyond Decentralized. It manages data Repositories
and controls data access by Applications. It provides:
- Object Relational Mapping (with Entity state management, SQL based querying and SQL and entity based persistence)
- API framework (that closes the Client/Server gap by passing entities directly and abstracts away communication details)
- Cross-Application transaction management and request & session management
- Synchronization of data across AIRport instances
AIRport runs entirely in-browser and can also run as a native application on end user devices. - AIRbridge is a supporting project. It will provide additional functionality
that is necessary for AIRport applications to function effectively:
- A private Blockchain for every Repository
- Single Sign On solutions
- Data transfer management and optimization
- Data validation
- AIRway is a supporting project that enables AIRport instances to operate in a peer-to-peer mode.
- Highway is an upcoming project that will let organizations work on data owned by local communities. It will facilitate community storage of data and integrate with AIRport for user owned data. Its development is driven by the idea that corporations can harmoniously work with locally owned community data providers and personal user data. Highway will take application interoperability into the distributed world, beyond what data decentralization can offer.
- Maglev is a future project. It's about letting any number of organizations fairly and securely access community owned data. It is meant to help existing organizations plug into locally sovereign data as well as group and personal data.
Autonomous Interdependent Repositories
Autonomous Interdependent Repositories are about taking relational data and breaking it up into pieces that can be shared across devices.
Any dataset presented to the user at a given time is limited. For example a thread on a forum is a limited set of data. Repository represents such a dataset. Repositories are meant to be small and focused.
Using data presentation as a guidance Applications define Repository boundaries. For example menu contents covered by one Repository while forum threads backed by separate Repositories.
Repositories can aggregate data computed based on contents of other repositories.
AIR - Relational
Repositories are loaded into relational databases. A Repository can span any number of relational tables.
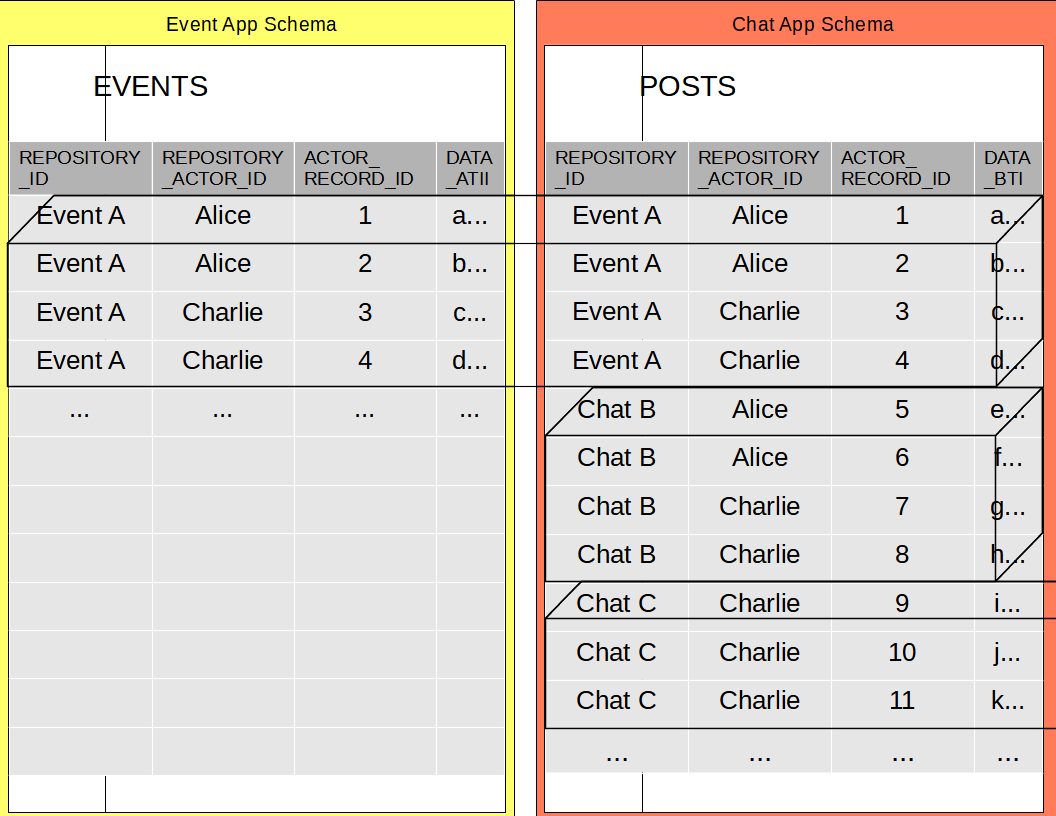
AIR - IDs
All records in Repositories are identified by 3 keys:
- Repository GUID - a globally unique identifier for the repository
- Actor GUID - a globally unique identifier for the "Actor" that created the record.
- Actor Record ID - a numeric identifier unique to the physical database on which the record is created
"Actor" is a User, using an Application on a Device. In practice it Actor is:
- A given User - identified by an email address.
- Using a given Application - identified by the URL of the Application (domain + path)
- via a particular Client - identified by the domain of the Client (Ex: "a-user-interface.com")
- on a particular Database - that resides on a User's device and is identified by a random GUID
Applications are different from Clients. Applications run in isolated IFrames (from different domains), within the AIRport tab. Clients are the UIs that use AIRport.
AIR - Transaction Logs
Repositories are stored "at rest" on decentralized file systems as Transaction logs. Each Repository gets its own, independent Transaction log. Transaction logs are structured in:
-
Transaction History - this is a record of the transaction, with a
unique identifier and a timestamp of when the transaction took place.
-
Operation History - records an operation
in a particular relational table. It has the schema and table names,
the GUID of the Actor that performed this operation, the operation type (Create/Update/Delete)
and the order of that operation in the current Transaction History
record.
- Record History New Value - has the column name and the value that is being Inserted or Updated in that column (for the record of the containing Record history)
- Record History Old Value - has the column name and the value that is being Deleted or Replaced (with an Update operation)
-
Record History - contains the Actor GUID and the
Actor Record Id for the record. The Actor GUID represents
the Actor that created the record and is needed for Update
and Delete operations. It may be different from the Actor who
performed the operation (stored in Operation History).
Each Transaction History carries with it all of the information on the Actors that performed the operations in that Transaction.
AIR - Autonomous
Repositories are Autonomous because each Repository contains all of the information needed to be useful. That is, it can be used by itself, without any other Repositories. This refers to the fact that Repositories may reference each other's records. That is, a record in one Repository may have a foreign key to a record in another Repository.
When a Repository references records from other Repositories those records get copied to the referring Repository. This is what allows the referring repository to remain autonomous. The copied records have the state of the original records as it was when they were copied. The new record copies may then be updated and may diverge from the state of the records they were copied from (in referenced Repositories).
The copy process is recursive for all records that are, in turn, pointed to by the foreign keys in the (top level) copied records. This means that no matter how deep the foreign key references go, they all get copied into the referring Repository.
This has the effect of making sure that Joins (made on the tables where the Repository resides) always return data for the views to display. Thus, a Repository may be loaded (and will always be usable) by itself, even if it has nested references to records in many other Repositories.
AIR - Interdependent
When records are copied into a Repository from other Repositories, the original Repository GUID, Actor GUID and Actor Record Id are retained in separate columns. Along with them, the global address of the Repository is retained as well, allowing AIRport to lookup the referenced Repository (the source of the originally copied records).
These "original" Ids are retained in another set of keys that do not have foreign key constraints on them. AIRport can then be instructed to take a given Query and run it in cross-Repository mode. When doing so AIRport will use LEFT JOINs and progressively load missing Repositories and re-query until it returns complete object graphs with all of the records from the original Repositories.
The query process may be slow (due to necessary network round trips to retrieve additional Repositories) but may be served via Observables, allowing the UIs to progressively load more data as it becomes available.
Thus Repositories are Interdependent and the UIs can make the choice of viewing the Repository-local data only, or loading the cross-Repository view, that may at first return Repository-local data and then can fill in the data across referenced Repositories.
AIRport
AIRport is a DApp Runtime. It encapsulates decentralized storage, provides API and persistence frameworks, and standardizes API calls.
AIRport implements Autonomous Interdependent Repositories. It provides a common runtime on which Decentralized Applications can run and be accessed by Clients such as Web UIs.
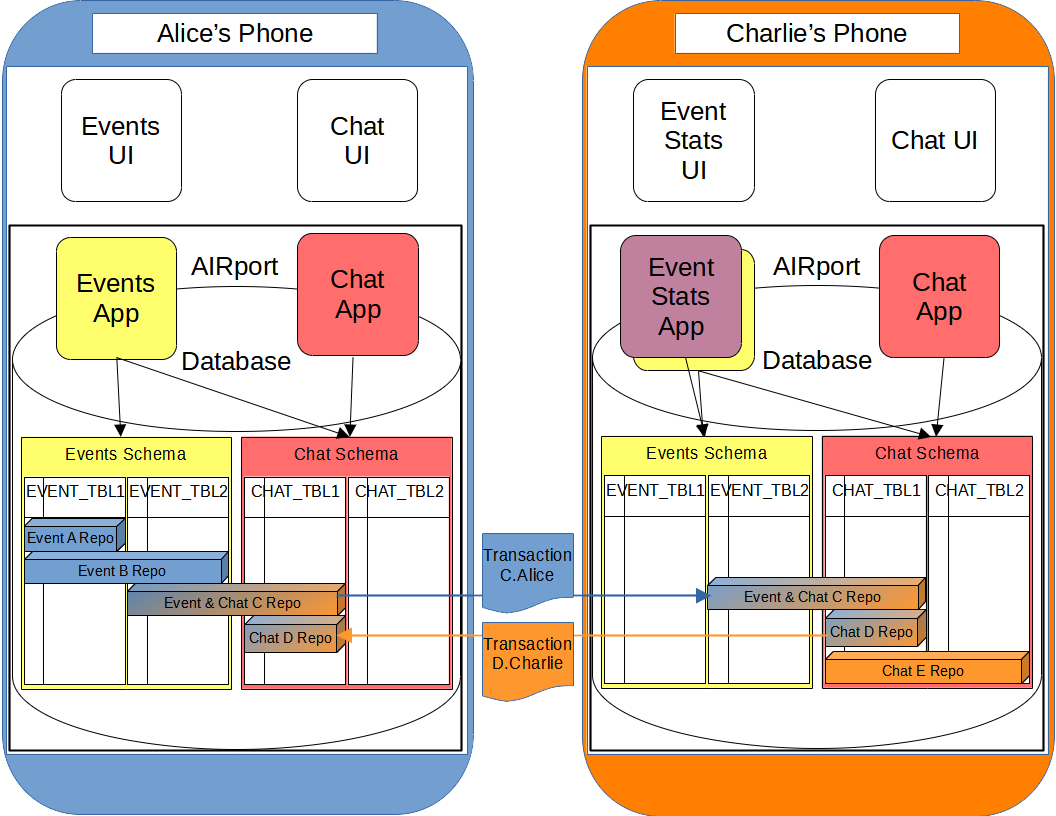
Alice has the Event App and the Chat App installed in AIRport ( on her device). Charlie has the Chat App and the Event Stats App installed on his device. The Event Stats App automatically installs the Event App and its schema.
The data for all three Apps is stored in Chat/Event specific Repositories, one repository per chat/event. Alice has "Event A" and "Event B" that are not shared with Charlie. Alice and Charlie share "Event C" and its chat. They participate in another "Chat D" that isn't associated with any event. Charlie has a "Chat E" that isn't shared with Alice.
The core functionality provided by AIRport is:
- Database ORMs and entity state management.
- API interfaces for UI-to-App and App-to-App interaction.
- Transactions & Scope.
- Cross-database data synchronization.
ORM & State
Default ORM framework for AIRport is Tarmaq. It provides:
- Entity Mapping API: Entity and Property decorators in JPA style.
- Query API: TypeScript integrated SQL statements with SELECT clause as entity tree.
- DAO API: Strongly typed entry points into the Query API.
AIRport supports creation of additional ORMs. All ORMs can return fully interlinked graphs of Entity objects. Support for traditional SQL result sets is also available.
AIRport has sessionless entity state management. All entity objects returned by the ORM contain a hidden property with the original state of the entity. When the entities are saved, AIRport calculates diffs on the entity objects (using the original object state) and performs the necessary updates. Tracking original state removes the need for maintaining Hibernate-like ORM sessions and insulates edited objects from possible state overwrites (due to remotely made updates to the same objects).
API
AIRport Apps run in isolated VMs inside AIRport. Clients (UIs) communicate with Apps via AIRport:
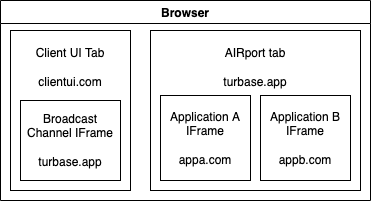
Apps define API methods by decorating them with @Api() decorator. AIRport generates SOAP like stubs for Clients and other Apps to use. Invoking those stubs sends requests to AIRport which forwards them to Apps where they are from (loading missing Apps when necessary). The default import of an Application contains just the API stubs. A separate bundle is created for Application itself (and is deployed as a standardized URL for AIRport to load into IFrames).
App VMs are run in IFrames. Because Application server domains differ, Apps are isolated from AIRport and other Apps (from different domains). The only way Apps can interact with AIRport and other Apps is via the API framework defined by AIRport.
Apps cannot directly access the relational database hosted by AIRport and must make standardized persistence requests (via provided ORMs) that are pre-processed and sanitized by AIRport.
Apps can join to tables in schemas of other Apps. Apps cannot directly modify data in schemas that belong to other Apps. Apps must call APIs defined by other Apps to make data modifications (in schemas of those other Apps).
Transactions & Scope
Every API call that goes through AIRport get's its own savepoint. This means that if an API method fails and throws an Error, all of its database operations (and operations of API methods it itself called) will be rolled back. If an API method is wrapped in a "try {} catch(e) {}" block, catching the Error will allow the calling API method to do additional processing (and database operations) even if its nested API calls failed.
Transaction tracking is implemented behind the scenes, without requiring the developers to pass transaction objects around. In the same way, request information for an API operations is also implemented in the background. API services and DAOs can just:
@Inject()
requestManager: RequestManager
Synchronization
AIRport handles synchronization of Repositories across multiple devices. If there are synchronization conflicts AIRport automatically resolves them based on modification timestamps (with latest modification winning) and records conflict resolutions and their outcomes in Repository transaction history. UIs can hook into that resolution history and notify the Users that there were conflicts. UIs can also present to the Users what the conflicting values were and allow the Users to manually overwrite automatic resolution outcomes.
AIRbridge
AIRbridge is a collection of libraries that will integrate AIRport with Applications and Storage platforms.
The currently scoped-out functionality to be provided by AIRbridge is:
- Per-Repository private blockchain.
- A convenient Single Sign On solution and a high security one.
- Optimized data transfer library with support for future use cases.
- Entity based validation library for closing the Client-Server gap.
Blockchain
Each Repository should be secured by its own private blockchain. Each Actor will sign its transactions with its own private key. Actor keys will be stored in a User specific Repository, dedicated to key storage. All key in this Repository will be encrypted by user's Master key.
A Repository can, optionally, be encrypted by a symmetric key. This key should be distributed to each of the Repository members.
Blockchains keep track of the order of the transactions. There may be multiple sub-chains, depending on the state of the chained Transaction Logs on each of the member relational databases. Automatic conflict resolution will put new blocks in the chain. The blockchain should be eventually consistent, always leading to a consistent state from all sub-chains.
SSO
There should be an easy and convenient way for Users to sign into their local AIRport instance. AIRbridge should implement Open ID protocol for validating users. There should be a convenient way for users to recover their passwords.
There should also be a high securty way to authenticate in AIRport that does not rely on third parties for handling sensitive data.
User Master key should be derivable from the User's password, which should be secure against sub-quantum attacks in the convenient implementation (Ex: 15 characters, numbers and special, different caseing) and resistant to quantum attacks in the high security implementation.
Transfer
There should be a way for data to be correctly and efficiently transferred between the Clients and the Apps within AIRport. It should protect Apps from any code injection and alike attacks. It should allow for passing API (method) parameter modifications back to the calling clients.
Data transfer should be designed with future use cases in mind. It should support multi-source scenarios where Client may query both a remote Application host (via server-side AIRport nodes) and a local (private) AIRport instance, at the same time.
The data transfer library should support all major decentralized storage technologies, free cloud storage solutions like Google Drive, and should also work in scenarios where Repositories are stored centrally.
Validation
Likewise, AIRport integrates data in the opposite (Client to Server) direction. The entity objects returned by APIs contain their original (previous) state (in a hidden/private property). The Client makes modifications to objects and sends them back. DAO.save calls then use the original (previous) state to determine which properties were modified. If the passed-in objects don't have the original state (or IDs) they are treated as new objects. DAO.save calls will persist all objects in the passed in object trees that are new/updated/to be deleted (as long as those objects are in the schema of the Application).
Seamless integration of client and server requires strict validation of all data that is passed into Application APIs. Validating with standard procedural code is both verbose and error prone. AIRbridge validation uses declarative programming and automation to distil validation logic down to its essence.
AIRport validation leverages the Database Entity definitions and provides a type safe API that declaratively describes the desired (valid) state of the passed in entity tree. AIRport provides a validation DSL (in the form of validation functions, tied to the JSON entity tree declaration). All passed in state that is not validated is automatically flagged. All objects that are not validated are excluded from persistence operations. Non-validated properties (with new/modified values) on validated objects cause validation to fail.
AIRway
User devices should be able to communicate directly with each other.
AIRport stores repositories in decentralized file systems. Keeping track of new modifications to these requires constant polling. This is slow and adds extra load on the storage providers, increasing costs. There should be a way for end user devices to communicate directly with each other. The devices should be aware of what Repositories are shared between them and should pass updates to those Repositories appropriately.
Highway
Highway is AIR for the server environment.
Goal of Highway is to let local communities own their data while allowing global users to search it and contribute to it. The initial use case for it is a social network where locally operated and owned franchises host community data.
Technologically this can be accomplished by leveraging existing technologies such as globally shardable CockroachDB and ScyllaDB databases. Autonomous Interdependent Repositories are used for integration with private user data, for performance benefits and to provide an eventual migration path to Maglev.
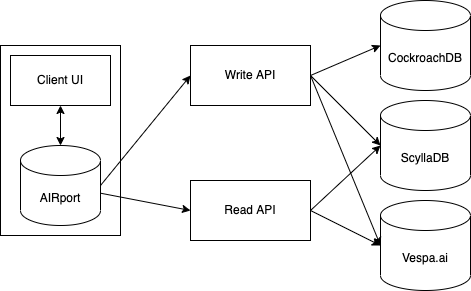
Highway will work by sending modification requests to the server, where they will be processed and placed into a distributed relational database. Because Highway data is stored in Repositories, read queries will go against a wide column store. Transaction logs will be pulled into the client-side AIRport engine where relational data will be reconstructed and queried. AIRport will monitor incoming transaction log entries and serve data via Observable feeds.
Highway will allow Applications from multiple providers to access and add to community owned data. Apps will access data across Application schemas and modify data in their own own schemas. This will be done based on rules specified by the community owned hosting franchises.
Applications will run in VMs and will have access to only the APIs specified by AIRport, thus preventing abuse of community data.
Maglev
Maglev is the AIR Internet. It connects Highway providers.
Maglev is about allowing organizations to interoperate in an ecosystem of Repositories.
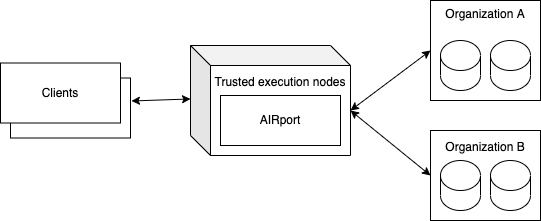
AIRport can run on a trusted network of execution nodes (a la blockchain validator nodes) and work with Repositories from multiple Organizations. Running AIRport on execution nodes ensures fairness and security of data processing and protects organizations and their data. AIRport can enforce data sharing and modification rules specified by each organization that hosts the data. Under those rules it can allow third party Applications access organization (and community) owned data. AIRport execution nodes can work in concert with Client-side AIRport engines to give views on decentralized data, combined with "organization distributed" data.
Blog
Check out the Blog for the latest developments in Beyond Decentralized technology.