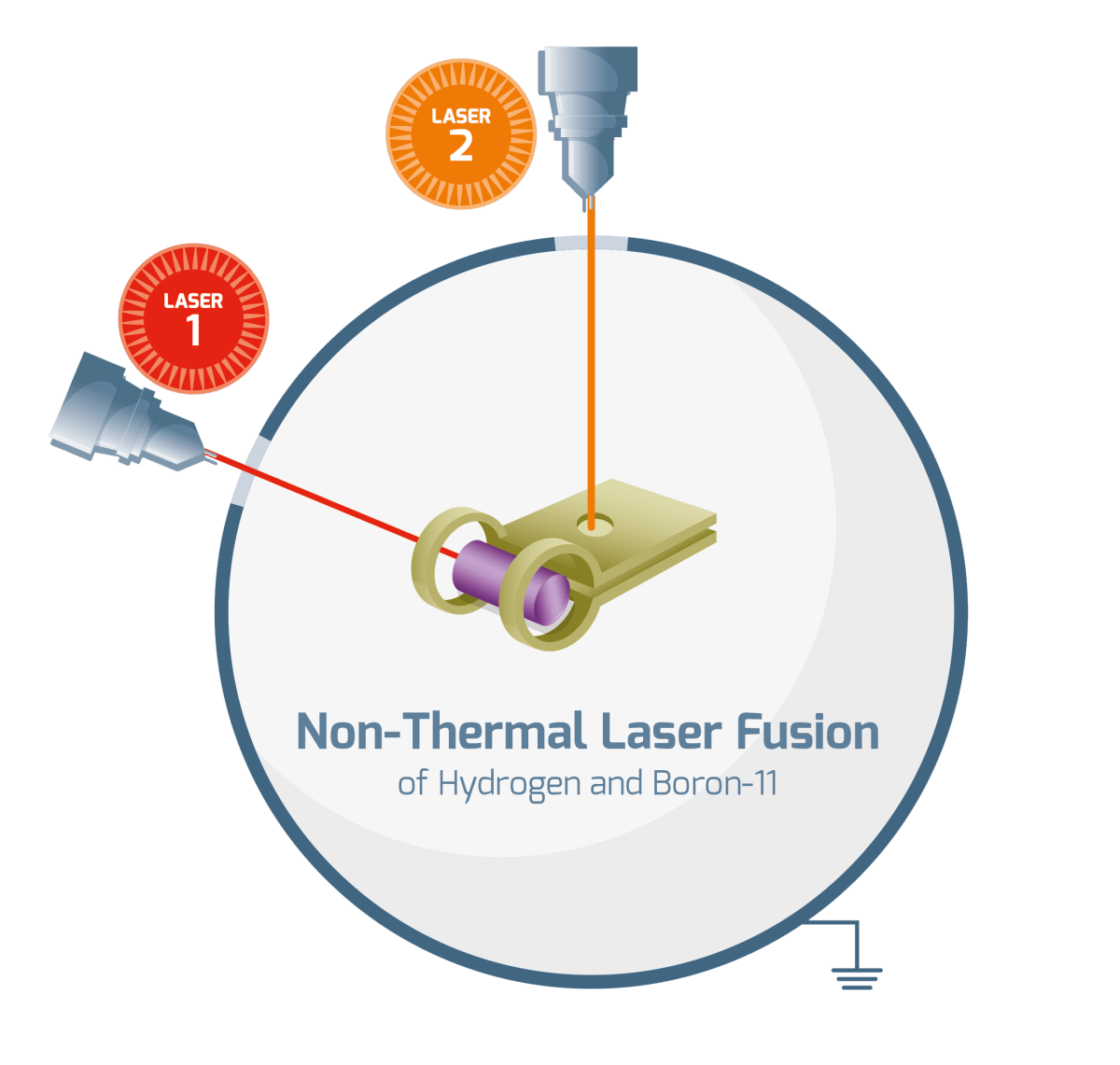
HB11 Energy is working on Hydrogen Boron-11 laser fusion .
Follow the Many to Ones
As the name states, Autonomous Interdependent Repositories are meant to be
interdependent. This basically means that records in one repository
can have columns with ids pointing to records in other repositories. In
itself its a simple concept however it presents a number of technical
issues when actually implemented.
This means that the records in the referencing repository have columns with ids that will be pointing to records that do not exist. And that is a "big no-no" in relational databases. In fact it's one of the main selling points for relational DBs is ensuring that such cases are not possible. So how to deal with this issue?
This shouldn't be too much of an issue given that AIRport framework is the sole point of entry into the database. Referential integrity can simply be checked by the framework. Though this does require additional queries and slows down the modification operation operations and thus certainly isn't an ideal solution.
Another issue with this solution is that when AIR is used in bigger installations (that might be aggregating data for many repositories) and may be accessed by tools other that AIRport framework, there is nothing that prevents data corruption (at least on referential integrity level). Or even for the case of Turbase - the advertisement engine will be written by a team of Statistical Analysis/AI experts that won't likely be using AIRport and instead use whatever ORM they prefer in Python.
This solves the referential integrity problem (Foreign Key columns will now point to these stub records). However this introduces another problem - what to do about fields in stub records that are stored in NON NULL columns?
Again, NON NULL constraints is one of the main selling points of RDBMS and disabling it just feels wrong. And again the framework can handle it (now at a lesser cost of enforcing NOT NULL constraints for non-stub records and not enforcing them for stub records). And again this presents a problem for third party tools. Alternatively NON NULL columns can be populated with default values (thus either requiring default values for all NON NULL columns or a special convention for defaults in NON NULL columns) but there is no way for third party tools to know what is a default stub value and what is a real value.
This approach solves both the Referential Integrity and NOT NULL constraint problems, without requiring any stub values. A new complication is presented in the form of maintaining fragmented records of the Repositories which are referenced via the @ManyToOne relationships. If those repositories are later loaded they will have to be replaced (unless they are in the same exact state as in the referenced records). The implementation of this approach will reveal any additional complications that may arise ...
Dealing with blank records
The core issue of having references to records in other repositories is the fact that those other repositories may not be present at the AIRport database in question.This means that the records in the referencing repository have columns with ids that will be pointing to records that do not exist. And that is a "big no-no" in relational databases. In fact it's one of the main selling points for relational DBs is ensuring that such cases are not possible. So how to deal with this issue?
Try 1: Disable referential integrity
My first thoughts on this issue were - let's just disable referential integrity in the database completely. This basically means no Foreign Keys. That does solve the underlying issue but at the cost of disabling all Foreign Keys completely, even for the records within a single repository.This shouldn't be too much of an issue given that AIRport framework is the sole point of entry into the database. Referential integrity can simply be checked by the framework. Though this does require additional queries and slows down the modification operation operations and thus certainly isn't an ideal solution.
Another issue with this solution is that when AIR is used in bigger installations (that might be aggregating data for many repositories) and may be accessed by tools other that AIRport framework, there is nothing that prevents data corruption (at least on referential integrity level). Or even for the case of Turbase - the advertisement engine will be written by a team of Statistical Analysis/AI experts that won't likely be using AIRport and instead use whatever ORM they prefer in Python.
Try 2: Create stub records
Later, when I revisited this issue another idea came to me - what about creating stub records instead. This means that there will now be records in the database which will be blank stubs and contain only the primary key columns in them (Repository Id + Actor Id + Actor Record Id).This solves the referential integrity problem (Foreign Key columns will now point to these stub records). However this introduces another problem - what to do about fields in stub records that are stored in NON NULL columns?
Again, NON NULL constraints is one of the main selling points of RDBMS and disabling it just feels wrong. And again the framework can handle it (now at a lesser cost of enforcing NOT NULL constraints for non-stub records and not enforcing them for stub records). And again this presents a problem for third party tools. Alternatively NON NULL columns can be populated with default values (thus either requiring default values for all NON NULL columns or a special convention for defaults in NON NULL columns) but there is no way for third party tools to know what is a default stub value and what is a real value.
Try 3: Follow the @ManyToOne's
I'm currently finishing the Repository implementation and as part of this effort I'm integrating the existing Votecube UI to have a real world AIRport scenario. And in doing so I've come to a realization that in order for repositories to be useful they will (at least sometimes) need the data in other repositories which pointed to with Foreign Keys. Thus a new idea came to me, why not just "follow" the @ManyToOne relationships and drag all of that data along?This approach solves both the Referential Integrity and NOT NULL constraint problems, without requiring any stub values. A new complication is presented in the form of maintaining fragmented records of the Repositories which are referenced via the @ManyToOne relationships. If those repositories are later loaded they will have to be replaced (unless they are in the same exact state as in the referenced records). The implementation of this approach will reveal any additional complications that may arise ...